
Back in August 2015 I posted information about how you can extract features from a map service. Since then, I have had many contact me about modifying the code so it can extract features beyond the record limit set in the map service. So today I decided to work on one that does!
To test the script, I headed over to the map services provided by the State of California GIS. Specifically, the one for wildfires:
http://services.gis.ca.gov/arcgis/rest/services/Environment/Wildfires/MapServer
When you scroll down a quick look will reveal that there is a maximum record count of 1000:

At the top, click on the “ArcGIS Online map viewer” link to take a look at the data. I changed my basemap to Dark Gray Canvas so the symbology really pops. Here is the area around Santa Clarita:
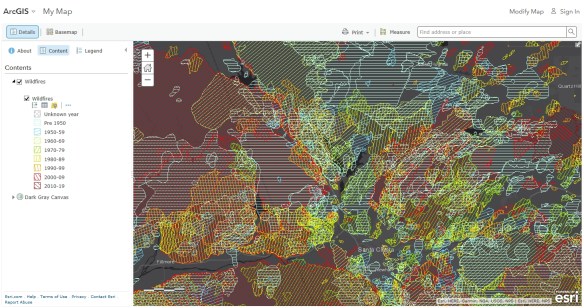
What a mess! There sure has been a lot of fires in this area. Clicking on the Show Table icon for the Wildfires layer will reveal how many records (wildfire polygons) I will need to extract:
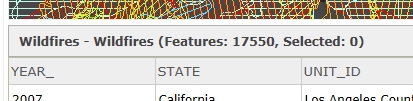
I will extract all 17,550 polygons with the following Python script:
import arcpy
import urllib2
import json
# Setup
arcpy.env.overwriteOutput = True
baseURL = "http://services.gis.ca.gov/arcgis/rest/services/Environment/Wildfires/MapServer/0"
fields = "*"
outdata = "H:/cal_data/data.gdb/testdata"
# Get record extract limit
urlstring = baseURL + "?f=json"
j = urllib2.urlopen(urlstring)
js = json.load(j)
maxrc = int(js["maxRecordCount"])
print "Record extract limit: %s" % maxrc
# Get object ids of features
where = "1=1"
urlstring = baseURL + "/query?where={}&returnIdsOnly=true&f=json".format(where)
j = urllib2.urlopen(urlstring)
js = json.load(j)
idfield = js["objectIdFieldName"]
idlist = js["objectIds"]
idlist.sort()
numrec = len(idlist)
print "Number of target records: %s" % numrec
# Gather features
print "Gathering records..."
fs = dict()
for i in range(0, numrec, maxrc):
torec = i + (maxrc - 1)
if torec > numrec:
torec = numrec - 1
fromid = idlist[i]
toid = idlist[torec]
where = "{} >= {} and {} <= {}".format(idfield, fromid, idfield, toid)
print " {}".format(where)
urlstring = baseURL + "/query?where={}&returnGeometry=true&outFields={}&f=json".format(where,fields)
fs[i] = arcpy.FeatureSet()
fs[i].load(urlstring)
# Save features
print "Saving features..."
fslist = []
for key,value in fs.items():
fslist.append(value)
arcpy.Merge_management(fslist, outdata)
print "Done!"
I put in a few comments so you could see how things are done where. This script also gives you some feedback as it runs. I will explain the script.
First, it loads the arcpy module as well as the urllib2 and json modules (we need those to open the url and read in the json output). In the Setup section, I set my baseURL variable to the wildfire map service layer 0 (you would change this line for the map service layer you are interested in), the fields variable to “*” to grab all the attributes, and the outdata variable to where I want to store my features, in this case in a file geodatabase and a feature class name of testdata (change this line to where you want to save your data, you can also specify a shapefile name instead).
Next, the script extracts the record limit for the map service and saves it to the maxrc variable. Next, the script grabs the id field name (which in this case is OBJECTID) and all the record id numbers are stored in the idlist variable. The id list is sorted and then the total number of records value is stored in the numrec variable.
Next, all the feature records are gathered up. This is done by taking the total number of records and stepping through them in chunks defined by the record limit. Since this map service has a limit of 1000, the first 1000 records are selected by the id field (OBJECTID) and saved to a temporary featureset fs[i]. It then cycles to the next 1000 records and stores those features, etc., until it reaches that last set. Note the if statement “if torec > numrec” is a fail safe when we reach the end and our to record number we calculate is higher than the maximum number of records, and if so, the torec value is set to the last record number in the list. After that, the loop is finished.
Finally, we loop through all the temporary featuresets to put them in a list and then pass that list to merge them all together to create our outdata. Whew!
Here is what my output looked like when I ran the Python script:

Note that as it gathers the features it shows you the queries it uses to do it, in 1000 record chunks. Also note that sometimes there are missing record numbers, probably because those records with certain OBJECTIDs were either edited and changed numbers or were deleted. So that is why you see in the first grab OBJECTIDs from 1 to 1003. It is not grabbing 1003 records, it is just that the first 1000 record numbers in the list start with OBJECTID 1 and end in OBJECTID 1003. Get it?
The script took a little over 3 minutes to run. Taking a look using ArcCatalog shows the gathered features:

And looking at the table shows I grabbed all 17,550 records and the attributes:

I hope this updated script will help you out with those map services that have record limits. Enjoy! -mike

This is good stuff Mike. How does the python script work with an app? In what way is it incorporated? Do you have any samples?
Thank you
Brandon Price
Hi Brandon. This python script does use the arcpy module, so it was written for use with ArcGIS. I have a Windows 7 machine, so I just run it at the DOS prompt. You could also just double click the script and it will run too. You could modify the script to not use arcpy at all, you would just need to load other modules that would allow you to save to a shapefile. I’m not sure if this script is app worthy, but I guess you could create one that would allow the user to input a map service URL and output format. I know you could turn this into a geoprocessing tool in ArcGIS with a few modifications. -mike
Hey Mike:
Thanks for the clarification. This is still a big benefit for me for ArcGIS Desktop. I was just wondering because I have an app that I might want to add a download widget to later on down the line.
Brandon
Thank you so much for sharing this! We are moving all of our services to AGOL, but have needs for local geoprocessing. This is just what I needed. I had to do some tweaks to get it to run using ArcGIS Pro’s Python 3 installation. I’d be happy to share those modifications if you’d like.
Sure, send me your Python 3 changes! -mike
Hi Micheal,
Thank you so much for all your efforts on this code, super cool! Unfortunately I am running into an issue right at the end of the script, I receive the following error: “Runtime error Traceback (most recent call last): File “”, line 49, in File “c:\program files (x86)\arcgis\desktop10.3\arcpy\arcpy\management.py”, line 4217, in Merge raise e ExecuteError: ERROR 999998: Unexpected Error.”
Line 49 in the code is “arcpy.Merge_management(fslist, outdata)”
And line 4217 in my management.py file is “raise e” (I can provide the previous lines if that’s helpful to you).
I know it’s likely impossible to troubleshoot all errors one could expect but I’m not sure if something jumps out at you. I’m not python expert so I appreciate any help you can offer.
I should also note, I copied and pasted your code exactly as you have it, within the python window in ArcGIS 10.3; only changing the path to the map service and where I desired to save my output data.
Thank you again!
~D
Hi Danielle. Either there is an anomaly in the map service data, or maybe the name you use for the outdata variable is not valid by ArcGIS standards. For example, does you data name have spaces in it? Sometimes that is a problem. Is it going to a .SHP file? If so, is it hitting some limits with the number of features or fields? Send me the map service path you are using and I can give it a try as long as I have access to it. -mike
Another thing that comes to mind is your computer. Maybe the environment on your computer is causing a problem. Does it have enough memory for all those temporary feature datasets before the merge? Is your hard drive fast enough? Have you tried using another computer to see if the code works? Have you tried upgrading ArcGIS Desktop to see if the problem goes away? I am using ArcGIS Desktop 10.5.1. Just some thoughts. -mike
Mike,
Thank you much! This is the service I’m using: https://gis.nassaucountyny.gov/arcgis/rest/services/ncgis/MapServer/13
I’m fairly certain it’s not locked down as I’m able to run a single query and download batches of a 1000 but there any many records (407,888) so doing this action 400+ times is prohibitive and makes your script all the more appealing 🙂
I’ve been sure to exclude any spaces in my naming conventions. I’ve attempted another, smaller map service as well but with the same result. Additionally I also attempted using your map service and simply changed the output path (again no spaces) to a geodatabase of the same name; still no luck there.
I also used another PC, as you suggest below, same result, but it’s also on the same computer network with the same ArcGIS build specs.
As far as my PC; I have a 64-bit OS with 8GB of RAM (7.88GB usable) and a 3.40GHz processor.
~D
Ok, so I think I know the problem … too much data! With 407,888 records, that means you will need enough memory to store it all, then basically merge all 408 temporary feature datasets into one. I don’t think you have enough memory OR merge cannot handle it all. I am going to try on my end with a hefty computer and see what happens to me!
Well it worked for me, go figure! I had 12gb of memory, but noticed it only consumed about half a gig when the script was almost done. I am using ArcGIS 10.5.1, so maybe that helped me? I saved the parcels to a geodatabase and it is only 88mb in size. Anyway, if you want the data I downloaded, feel free to email me at mcarson@burbankca.gov and I will send you a link.
Well imagine that! I appreciate you giving it a whirl! I definitely think it’s the Desktop versioning since I’ve tried map services with far fewer records and had the same result.
I’ll download the latest version and report back just in case others have the same issue.
Thank you for all of your efforts Mike!
I successfully updated my ArcGIS Desktop Version to 10.6 and still no luck with running the script. Wanted to let folks know if they run into the same error I posted above.
Hi Danielle. I’m sorry to hear that. I might have an idea you can try. Stay tuned!
Hi Danielle. I was thinking about your issue with the script. I still think it is a memory issue for you. Do you run the script inside ArcMap using the Python window? If so, try running the python script at the Windows DOS prompt instead (Windows cmd window).
Another option is the script below. It will save each feature extract instead of using memory, then it merges all the features together. Just modify the outdata variable and see if that works. Do note that it will leave a bunch of temporary feature classes in the geodatabase, each representing the 1000 feature extract. Give it a try.
import arcpy
import urllib2
import json
# Setup
arcpy.env.overwriteOutput = True
baseURL = “https://gis.nassaucountyny.gov/arcgis/rest/services/ncgis/MapServer/13”
fields = “*”
outdata = “C:/temp/data.gdb/ncgis_parcels”
# Get record extract limit
urlstring = baseURL + “?f=json”
j = urllib2.urlopen(urlstring)
js = json.load(j)
maxrc = int(js[“maxRecordCount”])
print “Record extract limit: %s” % maxrc
# Get object ids of features
where = “1=1”
urlstring = baseURL + “/query?where={}&returnIdsOnly=true&f=json”.format(where)
j = urllib2.urlopen(urlstring)
js = json.load(j)
idfield = js[“objectIdFieldName”]
idlist = js[“objectIds”]
idlist.sort()
numrec = len(idlist)
print “Number of target records: %s” % numrec
# Gather features
print “Gathering records…”
merge_list = []
for i in range(0, numrec, maxrc):
torec = i + (maxrc – 1)
if torec > numrec:
torec = numrec – 1
fromid = idlist[i]
toid = idlist[torec]
where = “{} >= {} and {} <= {}".format(idfield, fromid, idfield, toid)
print " {}".format(where)
urlstring = baseURL + "/query?where={}&returnGeometry=true&outFields={}&f=json".format(where,fields)
fs = arcpy.FeatureSet()
fs.load(urlstring)
tempdata = outdata + str(i)
print " Copying features…"
arcpy.CopyFeatures_management(fs, tempdata)
merge_list.append(tempdata)
# Save features
print "Saving features…"
arcpy.Merge_management(merge_list, outdata)
print "Done!"
We were having the same issue. Have you tried turning off the background processing in Geoprocessing Tab>Geoprocessing Options and then uncheck enable background processing.
Oh and thanks Mike that script helped a ton!
Thanks Bryan. I have background geoprocessing on and it works for me, I tested it. However, I do not run the script inside ArcMap using the Python window. I run it at the Windows DOS prompt. If Python is setup right in Windows, you can even double click the .py script and it will run too.
Mike, thanks for the additional info. I will definitely keep that in mind. My comment above was more in reference to possibly help Danielle out. I was not detailed enough in my previous response.
I was getting the same error Danielle had running the script through the python window in ArcCatalog which was the “Runtime error Traceback (most recent call last): File “”, line 49…..: ERROR 999998: Unexpected Error.”” But as soon as I disabled background processing (Geoprocessing Tab>Geoprocessing Options and then uncheck enable background processing) the script you provided worked exactly how it is supposed to.
Again, thank you Mike for sharing the script with us.
Hi Bryan. Thanks for the extra info. That will help others out if they try running it in the Python window in ArcCatalog or ArcMap.
Thank you again Michael & Bryan! I did as Bryan suggested, turned off the background geoprocessing and voila! it did the trick! No need to update the code, that was posted originally, aside from the service URL and my geodatabase location (of course). Y’all are the best!
The script worked perfectly! Very helpful. Thanks for sharing this !
Hi George. I’m glad it worked for you.
How would i insert a username & password into this code for a secure service shared with members of a group.
Hi Kegan. It is not too difficult, you just need to authenticate yourself with ArcGIS Server and get a token, then you use that token when you make HTTPS requests to secure map and feature services.
For example, to manually do this if an ArcGIS Server is setup for tokens (see http://maps.scag.ca.gov/scaggis/rest/services) you will see in the upper right corner a “Get Token” link. If you click on that, you will be taken to the tokens page (https://maps.scag.ca.gov/scaggis/tokens/) to enter a username and password to get a token from the server. Note you can specify the Client (I use RequestIP to limit my token to my current IP address), Expiration (I usually keep it to an hour), and Format (I use JSON). Once you get the token, you have access to the secured services at that site.
So how to do this in Python? First at the top of your code where you import the arcpy module, you need to import the requests module.
import requestsThen the code block to get the token looks like this:
tokenurl = "https://YOUR_ARCGIS_SERVER/tokens/"username = "YOUR_USERNAME"
password = "YOUR_PASSWORD"
params = {'username':username, 'password':password, 'client':'requestip', 'expiration':60, 'f':'json'}
tokenresponse = requests.post(tokenurl, data=params, verify=False)
data = tokenresponse.json()
token = str(data["token"])
Note for the params I set the client to “requestip”, the expiration to 60 (in minutes, so 1 hour), and my output format to “json”.
With the token now set in the token variable, you use that variable when you make requests to secure map and feature services. You do this by adding “&token=” to the calling URL with the token value after the equal sign. For example, using the code sample in this post, I would change the urlstring variable and add the token parameter:
urlstring = baseURL + "?f=json&token={}".format(token)and
urlstring = baseURL + "/query?where={}&returnIdsOnly=true&f=json&token={}".format(where,token)and also
urlstring = baseURL + "/query?where={}&returnGeometry=true&outFields={}&f=json&token={}".format(where,fields,token)That’s it!
Hi Michael
Thank you so much for the advice! I had to use Webapp means of authentification to generate a token (the requestIP generated token did not seem to work for some reason). I eventually got the process to work since my dataset had about 14 million verticies it kept giving me the following error:
“RuntimeError: RecordSetObject: Cannot open table for Load”,
Turns out i had to reduce my MaxRecordCount to increments of 500 and it worked!
Keep up the good work
Kegan
I keep getting an error when I run this code in ArcGIS Pro:
import arcpy
import urllib2
import json
# Setup
arcpy.env.overwriteOutput = True
baseURL = “https://gis2.idaho.gov/arcgis/rest/services/DPR/Idaho_Trails_MapC/MapServer/4/query”
fields = “NAME,OFFICE,HUNTING_UNIT”
outdata = “Q:\Temp\Mark_Temp\Idaho_Project\Idaho Trails Map\Trailheads.gdb/Automobiles2”
# Get record extract limit
urlstring = baseURL + “?f=json”
j = urllib2.urlopen(urlstring)
js = json.load(j)
maxrc = int(js[“maxRecordCount”])
print “Record extract limit: %s” % maxrc
# Get object ids of features
where = “1=1”
urlstring = baseURL + “/query?where={}&returnIdsOnly=true&f=json”.format(where)
j = urllib2.urlopen(urlstring)
js = json.load(j)
idfield = js[“objectIdFieldName”]
idlist = js[“objectIds”]
idlist.sort()
numrec = len(idlist)
print “Number of target records: %s” % numrec
# Gather features
print “Gathering records…”
fs = dict()
for i in range(0, numrec, maxrc):
torec = i + (maxrc – 1)
if torec > numrec:
torec = numrec – 1
fromid = idlist[i]
toid = idlist[torec]
where = “{} >= {} and {} <= {}".format(idfield, fromid, idfield, toid)
print " {}".format(where)
urlstring = baseURL + "/query?where={}&returnGeometry=true&outFields={}&f=json".format(where,fields)
fs[i] = arcpy.FeatureSet()
fs[i].load(urlstring)
# Save features
print "Saving features…"
fslist = []
for key,value in fs.items():
fslist.append(value)
arcpy.Merge_management(fslist, outdata)
print "Done!"
I get a error message:
File "”, line 16
print “Record extract limit: %s” % maxrc
^
SyntaxError: Missing parentheses in call to ‘print’. Did you mean print(“Record extract limit: %s” % maxrc)?
I’ll change these out but will still give me a syntax error.
When I run the same code in ArcMap 10.3.1 I recieve this error:
Runtime error
Traceback (most recent call last):
File “”, line 15, in
KeyError: ‘maxRecordCount’
I’m not sure what I’m doing wrong, any advice?
Hi Mark. The code was made to run in Python that comes with ArcGIS Desktop (ArcMap), not ArcGIS Pro. ArcGIS Pro uses Python 3.6.x while ArcGIS Desktop uses 2.7.x, so the code would need to be modified to work in Python 3 and ArcGIS Pro. As for the error you are getting using ArcMap, I would have to give it a try and see what is going on. -mike
Mark, remove the “/query” from your baseURL variable. It is messing up the code when it tries to query the map service to get the max record count. If you want to run in ArcGIS Pro, you will need to modify all the print statements to the new print function print( ). -mike
this is terrific! good job!
Thanks Joe! -mike
Hi Michael,
Thank you so much for the two posts to extract features from a map services.
I’ve been trying to get the information from a mapserver with Python 2.7.3 from ArcGIS 10.2 but I’m getting an error when I run it:
Record extract limit: 1000
Number of target records: 11175
Gathering records…
ESRI_OID >= 1 and ESRI_OID <= 1000
Traceback (most recent call last):
File "C:/Users/ecarrillo/Downloads/Extraer_IGME_BDMIN_Indicios_II_(ID-0)_bis.py", line 48, in
fs.load(urlstring)
File “C:\Program Files (x86)\ArcGIS\Desktop10.2\arcpy\arcpy\arcobjects\arcobjects.py”, line 173, in load
return convertArcObjectToPythonObject(self._arc_object.Load(*gp_fixargs(args)))
RuntimeError: RecordSetObject: Cannot open table for Load
How can I solve it.
Thanks,
Eloy
Hi Eloy. This error occurs when no features are returned. What is your baseURL variable set to? It is possible it is not set correctly or the map service is secure and requires a login.
Hi Michael,
Thanks for the quick answer. M baseURL is:
http://mapas.igme.es/gis/rest/services/Cartografia_Tematica/IGME_BDMIN_Indicios/MapServer/1
I don’t think the map service is secure because normaly, I’ve applied the algorithm of the previous post to extract the first 1000 values, and it’s work perfectly. Then for extract the other values I used to change the line where=”1=1″ by where=”objectid>=1000+and+objectid<1999&f=json" and I subsequently varying from 1000 to 1000 until have all the elements. The ol roblem it's when you have a lot of elements.
Thanks,
Eloy
Eloy, it looks like that server is very slow at times. I get a “504 Gateway time-out” error. When that happens no features are returned and the python script errors out. There is nothing much you can do unless they fix their server’s response to internet traffic. -mike
Eloy, since I do not like to let the computer win, after some experimenting, I was able to get the script to work with that map service. You will need to make the following modifications for it to work.
First, change the maxrc variable to 50 and comment out the rest:
maxrc = 50 #int(js["maxRecordCount"])I found gathering 50 records at a time from the map service instead of 1000 helped the map service keep up with little delay.
Next, you need to add an oidlist variable and oids variable to the code, as well as modify the urlstring variable, all in the “Gather features” code block. Here is what I did:
Instead of selecting records using a range of ids in a field, you specify the exact ids to pull out separated by a comma (like 1,2,3,4,5,6). Note the urlstring variable was changed to query the objectIds parameter instead of using the where parameter in the original code. For some reason this map service hates pulling records using the where parameter, but works using the objectIds. I also included a print statement so you can see the value of the oids variable when it is passed to the map service query.
Give this a try. It worked for me. Since this pulls out by 50 record chunks, it does take a while to run, but you get all 11175 point features. -mike
Hi Michael,
Thanks you very much, the script works perfectly.
Keep up the good work and thanks you again
Eloy
You are welcome! Always here to help.
Hi, Michael, im getting other error after modify the script.
Traceback (most recent call last):
File “C:\Python27\ArcGIS10.5\Lib\site-packages\pythonwin\pywin\framework\scriptutils.py”, line 326, in RunScript
exec codeObject in __main__.__dict__
File “D:\JuanJulio\Cursos\PennState\GetFeatures_v2.py”, line 23, in
idfield = js[“objectIdFieldName”]
KeyError: ‘objectIdFieldName’
This is the feature service im trying to download:
http://geocatmin.ingemmet.gob.pe/arcgis/rest/services/SERV_GEOLOGIA_REGIONAL/MapServer/5
I hope you could help me. Maybe im missing something in the script.
Thank you.
Hi Juan. That map service is pretty slow, and I get the error too. You can take a look at the layer in the map service using the ArcGIS Online map viewer:
http://www.arcgis.com/home/webmap/viewer.html?url=http%3A%2F%2Fgeocatmin.ingemmet.gob.pe%2Farcgis%2Frest%2Fservices%2FSERV_GEOLOGIA_REGIONAL%2FMapServer&source=sd
You can also open the attribute table to take a look at the data.
There are only 15 polygons for that layer, however those polygons are very large so you have a massive amount of shape points per polygon. You would need to modify the python script to download each OBJECTID individually instead of a range of object IDs to see if that works for that particular map service. I just modified this section in the code:
I’m running mine now. It is only on record 5 and has been running for about an hour! Good luck! -mike
Hi Michael,
I am trying to extract features from a Map Server using the python script. I am thinking it is not working due to I am using QGIS. I am not at all familiar with python and scripting. I was not able to find out how many feature are in the layers but it will not let me download them a json file. If you could help that would be great.
The map server is in Georgian but that should not matter.
Here is the link http://gisappsn.reestri.gov.ge/ArcGIS/rest/services/WebMap/MapServer
I need to extract the Layer number 1 and 2. 1 is equal to Sectors and 2 is equal to quarters.
Either shapefile or geojson would be fine.
OH. the spatial reference of the data is 32638 and I would like the output to be 4326.
Thanks so much if you can help.
Dana
Hi Dana. I believe the map services are setup so you cannot extract data. I could not get anything out of them.
Hi All, how do you modify this code to only extract features that intersect a user input geometry envelope?
Hi Laura. You would add the following parameters to the urlstring variable in the “Get object ids of features” section and “Gather features” section:
&geometryType=esriGeometryEnvelope
&geometry=xmin,ymin,xmax,ymax
&spatialRel=esriSpatialRelIntersects
Where xmin,ymin,xmax,ymax are the coordinates that the map service is in. I would add them just before the “&f=json” parameter in the URL string. If you want to use latitude/longitude (WGS84) instead, make sure to add the following input spatial reference parameter as well:
&inSR=4326
4326 is the WKID for the WGS84 spatial reference (http://spatialreference.org/ref/epsg/4326/)
If you want to know more about the query parameters for ArcGIS map services, see https://developers.arcgis.com/rest/services-reference/query-map-service-layer-.htm . -mike
Worked like a gem! Thanks so much, this will be a life saver.
Mike,
This worked so well I had to leave a reply! Thank you so much, this is an amazing piece of code and between this post and your other “Extracting Features from Map Services” walk-through, its incredibly easy to implement even for novice coders such as myself. Thank you so much for contributing to the community and sharing this!
-Kyle
You are welcome Kyle! And Happy New Year! -mike
Hi Mike, Happy New Year to you as well!
I’ve successfully used the script multiple times now for different data sets and it has worked flawlessly with the following exception. There was one data set which produced the following error and I was wondering if there is something in the script that could be modified to fix the error:
Python 2.7.14 (v2.7.14:84471935ed, Sep 16 2017, 20:19:30) [MSC v.1500 32 bit (Intel)] on win32
Type “help”, “copyright”, “credits” or “license” for more information.
>>> execfile(r’C:\MapService_Extract\script.py’)
Record extract limit: 1000
Number of target records: 11380
Gathering records…
OBJECTID >= 7372781 and OBJECTID <= 7373780
Traceback (most recent call last):
File "”, line 1, in
File “C:\MapService_Extract\script.py”, line 42, in
fs[i].load(urlstring)
File “C:\Program Files (x86)\ArcGIS\Desktop10.6\ArcPy\arcpy\arcobjects\arcobje
cts.py”, line 175, in load
return convertArcObjectToPythonObject(self._arc_object.Load(*gp_fixargs(args
)))
RuntimeError: RecordSetObject: Cannot load a table into a FeatureSet
>>>
The map server URL with the data set I was attempting to extract is here:
http://www.cobbgis.org:81/arcgisext/rest/services/water/waterlivemapwm/MapServer/43
It seems odd because many of the layers hosted by this same map server extract just fine but the storm water layers seem to be the ones returning the error.
Thanks for your help!
-Kyle
Hi Kyle. I have run into a few of these before. Looking at the high values of the record numbers … and the name of the map service … the data seems to be edited live which means old records that have been deleted or changed tend to stick around until they reconcile the data. That leaves you with a bunch of blank records not associated with any features, so there is nothing to save, thus the python script errors.
The script would need to be modified to check if any features were selected first within the object id range (a feature count greater than zero), then if so, save the features and move on to the next group. If not, don’t save anything but move on to the next group. If you make any changes to the script to test for something selected, please share in this comments section! -mike
Hi Miike. I tried just adding an exception to see if the script would go to the next record batch and gather any records that could be successfully loaded into the feature set, but it never seemed to find any records that could be loaded which makes me wonder if the issue really is blank records or if there is something else going on. I have very little understanding of arcpy (and my general python knowledge is limited as well) so please bare with me if my change to the code is not doing exactly what I think it’s doing. I am now using a different layer for testing which has far fewer total records:
http://www.cobbgis.org:81/arcgisext/rest/services/water/waterlivemapwm/MapServer/39
This was what I changed in the script:
# Gather features
print “Gathering records…”
fs = dict()
for i in range(0, numrec, maxrc):
torec = i + (maxrc – 1)
if torec > numrec:
torec = numrec – 1
fromid = idlist[i]
toid = idlist[torec]
where = “{} >= {} and {} >> execfile(r’C:\MapService_Extract\script_long.py’)
Record extract limit: 1000
Number of target records: 11380
Gathering records…
OBJECTID >= 7384381 and OBJECTID = 7385381 and OBJECTID = 7386381 and OBJECTID = 7387381 and OBJECTID = 7388381 and OBJECTID = 7389381 and OBJECTID = 7390381 and OBJECTID = 7391381 and OBJECTID = 7392381 and OBJECTID = 7393381 and OBJECTID = 7394381 and OBJECTID = 7395381 and OBJECTID <= 7395760
No records gathered, moving to next set!
Saving features…
Traceback (most recent call last):
File "”, line 1, in
File “C:\MapService_Extract\script_long.py”, line 52, in
arcpy.Merge_management(fslist, outdata)
File “C:\Program Files (x86)\ArcGIS\Desktop10.6\ArcPy\arcpy\management.py”, li
ne 4487, in Merge
raise e
arcgisscripting.ExecuteError: Failed to execute. Parameters are not valid.
ERROR 000400: Duplicate inputs are not allowed
Failed to execute (Merge).
Any thoughts would be appreciated! Thanks,
-Kyle
Oops, I apologize, my comment seems to have formatted oddly, my change to the code was this:
# Gather features
print “Gathering records…”
fs = dict()
for i in range(0, numrec, maxrc):
torec = i + (maxrc – 1)
if torec > numrec:
torec = numrec – 1
fromid = idlist[i]
toid = idlist[torec]
where = “{} >= {} and {} <= {}".format(idfield, fromid, idfield, toid)
print " {}".format(where)
urlstring = baseURL + "/query?where={}&returnGeometry=true&outFields={}&f=json".format(where,fields)
fs[i] = arcpy.FeatureSet()
try:
fs[i].load(urlstring)
except RuntimeError:
print "No records gathered, moving to next set!"
Hi Kyle. It seems that map service is not returning any geometry at all, just attributes. Not sure why. You would not be able to extract any features anyway.
Hi Michael,
It is a great tool. I tried in 10.1 and works perfectly. However in 9.3 version it does not, Do you know why?.Shoud I change some commands?. Thanks a lot!
Hi Patricio. ArcGIS 9.3 was a totally different animal. Instead of arcpy, it used the arcgisscripting module. You would have to create new code for all the arcpy commands. For more information on arcgisscripting, dig around in the old 9.3 help here: http://webhelp.esri.com/arcgisdesktop/9.3/index.cfm?TopicName=About_getting_started_with_writing_geoprocessing_scripts . Maybe that will help you out. -mike
Hi Michael,
I tried running this script and it looked to be almost successful, but it failed towards the end with a SyntaxError: Invalid syntax, but I’m not sure where the invalid syntax is:
(lots and lost of previous text)
OBJECTID >= 50001 and OBJECTID >> # Save features
… print “Saving features…”
Saving features…
>>> fslist = []
>>> for key,value in fs.items():
… fslist.append(value)
… arcpy.Merge_management(fslist, outdata)
File “”, line 3
arcpy.Merge_management(fslist, outdata)
^
SyntaxError: invalid syntax
>>> print “Done!”
Any suggestions?
Hi Chris. I see prompts “>>>”, are you entering each command by hand? Or are you running it inside the ArcGIS python window? Try running it in a windows command window instead and see what happens. It seems to error on the merge_management command.
Looking a little closer at your code, looks like you made the arcpy.Merge_managment command part of the for key,value loop. Take that out of the loop (remove the spaces before it) and the script should run without error. -mike
Love this script, use it loads. Thank you!
Is there anyway to run it against the entire Map Server? Ending the url in mapserver instead or mapserver/39? I’d like to be able to create a local gdb mimicking the map server without have to run the script 50 times. Any help is greatly appreciated! Thanks again!!
Hi Brita. You would need to program your python script to read in all the layer numbers for a particular map service, then iterate through the layers to capture the features in each. I do not have time to figure that out right now, but you can check out the API reference to see if you can. Just go to the map service URL that lists all the layers in the map service, then click on the API Reference link in the upper right, then click on “All Layers and Tables” to read about how to get a list. You would need to read in this list and grab the layer IDs which you would then use to iterate through each with the script. Good luck and do post your solution! -mike
i was try this script, but i got error
Traceback (most recent call last):
File “D:\CBI\Master\download_data.py”, line 43, in
fs[i].load(urlstring)
File “C:\Program Files (x86)\ArcGIS\Desktop10.1\arcpy\arcpy\arcobjects\arcobjects.py”, line 172, in load
return convertArcObjectToPythonObject(self._arc_object.Load(*gp_fixargs(args)))
RuntimeError: RecordSetObject: Cannot open table for Load
please help me
i was try, but i got error
Record extract limit: 1000
Number of target records: 34
Gathering records…
FID >= 0 and FID <= 33
Traceback (most recent call last):
File "D:\CBI\Master\download_data.py", line 43, in
fs[i].load(urlstring)
File “C:\Program Files (x86)\ArcGIS\Desktop10.1\arcpy\arcpy\arcobjects\arcobjects.py”, line 172, in load
return convertArcObjectToPythonObject(self._arc_object.Load(*gp_fixargs(args)))
RuntimeError: RecordSetObject: Cannot open table for Load
can help me to ressolve this?
thanks
Hi Nasmi. What is the map service you are trying to access in your code?
i’m trying to access
http://geoportal.menlhk.go.id/arcgis/rest/services/KLHK/Kawasan_Hutan_mei2019/MapServer/0
Nasmi, I’m getting completely different output from you with no errors. I have a total of 166240 records but you have 34. Make sure you are using the code in the article and set it up using the map service you gave me. Mine is running fine, here is the beginning of my output:
Record extract limit: 1000Number of target records: 166240
Gathering records...
FID >= 0 and FID <= 999
FID >= 1000 and FID <= 1999
FID >= 2000 and FID <= 2999
FID >= 3000 and FID <= 3999
...
It will take some time to run because of the high number of records. -mike
i was try and succed, but didnt still end because i got error again
Record extract limit: 1000
Number of target records: 166240
Gathering records…
FID >= 0 and FID = 1000 and FID = 2000 and FID = 3000 and FID = 4000 and FID = 5000 and FID = 6000 and FID = 7000 and FID = 8000 and FID = 9000 and FID <= 9999
Traceback (most recent call last):
File "D:\CBI\Master\coba.py", line 42, in
fs[i].load(urlstring)
File “C:\Program Files (x86)\ArcGIS\Desktop10.1\arcpy\arcpy\arcobjects\arcobjects.py”, line 172, in load
return convertArcObjectToPythonObject(self._arc_object.Load(*gp_fixargs(args)))
RuntimeError: RecordSetObject: Cannot open table for Load
can you help me, how to ressolve this? and If i just want to download 10.000 record data not all, what code i must to change?
Thanks for your help
Nasmi, unfortunately you are dealing with a slow map service because the polygon data is massive and some polygons have thousands of shape points. Take a look at previous questions about how to tackle map services with large amounts of features. It shows how to modify your code. -mike
Dear Mike
When i try to access a small data
http://geoportal.menlhk.go.id/arcgis/rest/services/test/Admin_Provinsi/MapServer/0
i got error too
Record extract limit: 1000
Number of target records: 34
Gathering records…
FID >= 0 and FID <= 33
Traceback (most recent call last):
File "D:\CBI\Master\coba.py", line 42, in
fs[i].load(urlstring)
File “C:\Program Files (x86)\ArcGIS\Desktop10.1\arcpy\arcpy\arcobjects\arcobjects.py”, line 172, in load
return convertArcObjectToPythonObject(self._arc_object.Load(*gp_fixargs(args)))
RuntimeError: RecordSetObject: Cannot open table for Load
can you help this error
Nasmi, this is another example of a slow map service and huge polygons that have thousands of shape points. Since there are only 34 records, in this case I would modify the maxrc variable to equal 1:
maxrc = 1
It should step through each of the 34 polygons to create your data. Other than that, I cannot help any further. -mike
Hello, that is a great code and a great inspiration, but I want your help. When I run the code shows me this error:
Record extract limit: 1000
Number of target records: 3702326
Gathering records…
POG_CODE >= 1 and POG_CODE <= 1000
Runtime error
Traceback (most recent call last):
File "”, line 42, in
File “c:\program files (x86)\arcgis\desktop10.4\arcpy\arcpy\arcobjects\arcobjects.py”, line 175, in load
return convertArcObjectToPythonObject(self._arc_object.Load(*gp_fixargs(args)))
RuntimeError: RecordSetObject: Cannot load a table into a FeatureSet
I tried lots of things but nothing could you please help me?
Thank you again, have a nice day!
Hi Tzirineto. You really want to extract over 3.7 million records? Good luck! What map service are you trying to use? Others had the same issues as you. The answer to your issue will be in comments above yours. Just read them to find out what to do for your situation. -mike
Hello the url is: http://gis.epoleodomia.gov.gr/arcgis/rest/services/Rimotomika_Sxedia_Poleod_Meletes/PoleodomikesGrammes/MapServer/0
I have read the above comments but again nothing. I want to exceed the maxrecord count and get a json file to add it in arcmap or qgis. Can you help me?
You cannot exceed the max record count of the map service. If it is set to 1000, you can only extract 1000 or less records at a time. I suggest you change the maxrc variable in the Python script to something like 200, just change the code to maxrc = 200, or whatever number you want. Maybe extracting smaller groups of records will help, but will take a very long time in your situation since you are dealing with over 3.7 million records. I suggest you try contacting the organization that maintains the map service and see if you can get a copy of the data from them instead. -mike
Hi Michael,
Can you help me extract the table from the REST map service and save it as a tabular data in Geodatabases or table in ArcGIS using Arcpy?
Hi Dhananjayan. What is the map service and table you want to extract?
Hi Michael,
Is this script still possible to extract 1 million records?
The REST Service is the following: https://ocgis.com/arcpub/rest/services/Geocode/OC_Address_Points/MapServer/0
Thanks.
-Eva
Hi Eva. It can, but will take a long time since that map service only allows 1000 records at a time. Also everything is saved into memory before merged together and saved, so potentially you could use up your memory on your computer if you don’t have a whole bunch! The other option is instead of saving to memory, you modify the code to save to a geodatabase for each 1000 record query. In one of the comments I talk about how to do that. Good luck! -mike
Sorry for the late reply, but thank you for the response Michael. I was able to use this and it helped immensely! This was great. Thank you for providing this!
Hi Michael,
Thank you for your wonderful code, this was super helpful. I was wondering if you could help me, I am running into some issues with running the code for one of the layers I wanted to download. Here’s the map service link:
https://arcgis.sd.gov/arcgis/rest/services/DENR/NR69_Observation_Wells_Public/MapServer/1
The error that I’m getting is:
Runtime error
Traceback (most recent call last):
File “”, line 23, in
KeyError: ‘objectIdFieldName’
The first part of the code I’m able to run and it returns the extract limit (2000). There’s over 5 million records on this so I changed the code to save to a gdb to save on memory usage.
I saw someone had a similar error to mine in the comments, I changed the code to what you had suggested for downloading each object ID individually but still came with this error. I consulted with some friends and they suspect that this error might be due to not having unique Object IDs. I’m fairly new to python so forgive me if any of my questions seem elementary.
Thanks,
Annie
Hi Annie. So that layer in the map service has 5,506,335 points! When the code tries to gather all the object ids for each of those points, their server times out. There are just too many records for their server to return. You have two options. First, you could contact the owner of that server/data and ask them if they would cut you a copy of the data. If you don’t want to do that (or you know they would not share with you), then you have to be a little creative with the code. Let me know if you want to go the creative code route. -mike
Hi Mike,
Thanks for your reply, I think I want to get a little creative with the code, I would have to go through several people and emails to ask for permission otherwise. I also would like to know more about how to solve this using code. Let me know if there’s any way I can help. No problem to drop this if this turns out to be a huge time sink for you, I’m grateful you’re taking the time to help me!
Thanks again,
Annie
OK, creative code it is! Since you will be dealing with over 5.5 million records, make sure to modify your code to save to a geodatabase instead of memory … see my post in the comments above on May 16, 2018.
Now the fun part. We found that trying to get their server to give us a list of all record numbers was making the query timeout, so we need to find the first record number and last record number for ourselves. Visiting https://arcgis.sd.gov/arcgis/rest/services/DENR/NR69_Observation_Wells_Public/MapServer/1 we scroll down to the bottom of that page and there is a field named OBJECTID, which as an ArcGIS user you know that holds the unique record numbers for any GIS data. At the bottom of the page note there is a Supported Operations section. Click the Query link. This is actually the page that the script uses to query the data. To find the first record number, enter in the Where input field the expression OBJECTID = 5506402, Return IDs Only to True, and Return Count Only to False. Click the Query (GET) button again. Boom! Scroll down to the bottom and you will see the last record number. As of this writing it was 5528141 for me, but it might be different for you since they keep editing the data that number will change. Make a note of it.
Now you need to modify your code. In the “Get object ids of features” section, comment out the code from “where =” to “idlist =” (that is put a # before each line) and change the line idlist = js[“objectIds”] to idlist = range(1, 5528141 + 1). Your last record number might be different, so put that in.
That should do it. If you want to test, try changing the idlist variable to something like idlist = range(1, 4000 + 1). That would pull out the first 4000 records, should run really fast and you can see the results. If it looks good, change the idlist variable back to the full record count and sit back for a few days I bet! Should it blow up during the run, you can look at the geodatabase to see what set of records numbers were saved and start the range from there in your code to continue! Good luck! And tell us how long it took! -mike
Hi Mike,
So sorry for my late reply, thank you so much for your suggested edits. I’ll let you know how it goes, thanks again for your help!
Hi Mike,
Here’s my update on how the code went. So I did what you had advised to do, comment out parts of #Get Object Ids in the code and replace with the id list range. I got the error “NameError: name ‘idfield’ is not defined”, so I put back in idfield = js[“objectIdFieldName”]
I got another error that said, KeyError: ‘objectIdFieldName’. I tried replacing with OBJECTID and that didn’t work, and I tried troubleshooting this for a while before finally giving up.
I have another work-around that finally did work, and that was using Feature Class to Feature Class tool in ArcGIS Pro. After logging in ArcGIS Pro, I put in the url for my feature layer as the Input and ran the tool to output shapefiles (https://arcgis.sd.gov/arcgis/rest/services/DENR/NR69_Observation_Wells_Public/MapServer/1/). This worked and it took me approximately 1 hour to run the whole thing. Note that I had to try this out a couple of times, the tool kept failing and gave me the error “000210: Cannot create output ” and for some reason it worked one day, I’m not sure why to be honest. Anyways thanks for your incredible help again, the code may not have worked for this layer, but it helped me a lot with my other layers.
Hi Annie. I’m glad you found a workaround!
Hallo mike : please scribt for : http://geoportal.menlhk.go.id/arcgis/rest/services/KLHK/Penutupan_Lahan_Tahun_2018/MapServer …i failed on objectid=476 ; and the question : if only has one objectid, but more than 3000 features, how to access it? example: http://geoportal.menlhk.go.id/arcgis/rest/services/KLHK/Lahan_Kritis_2018/MapServer
Hi Farin. The script works as designed and will handle map services with more than 3000 features for sure. Unfortunately, that map service you are trying to access is very slow/has gigantic polygon features and sometimes does not respond to queries, so the code will error out. You can look at the other comments posted here about modifying the code to deal with slow map services (for example, change the maxrc variable = 2), or better yet, you might want to contact whoever owns the map service and data and ask if they will give you a copy.
To handle any errors that might occur during feature extraction, you can modify the code fs[i].load(urlstring) to the following:
At least that would catch the error and alert you, then continue on to try and fetch the rest. Good luck. -mike
How do you modify the code so that the output it outputs spatial coodinates, such as WGS84?
Also whenever I list GLOBALID as my fields, it will not output. I tried setting arcpy.env.preserveGlobalIds = True but it has no effect.
Hi Gerry.
To output the geographic data in a different spatial reference, just add the &outSR argument to the query string for the urlstring variable. For WGS84, add &outSR=4326 to the query string.
As for GLOBALID fields, I do not believe they can be output unless it is a Feature Service.
Hello Milke,
Thanks for the article. It has been really helpful. Is there a way to select parcels by location from a map server. I have a set of points where I would like to select parcels(from map server) within 500 feet of the point. The map server has about 5.5 Million parcels and maxCount of 5K, so I assume its a bit tedious to download them as a feature set locally and run Select By Location. Wondering if you’ve come across similar situation. Appreciate any ideas.
Hi Abhi. I have not done it myself, but you can select by a point using a buffer. See the request parameters geometry, geometryType, inSR, and units in the ArcGIS REST API: https://developers.arcgis.com/rest/services-reference/query-map-service-layer-.htm . You just add them to the URL using &, like &geometryType=esriGeometryPoint&geometry=-104.1,35.6 . Good luck!
Yes Mike, I was able to apply spatial filter like you said. It worked out beautifully. Given the size of the data, instead of creating a feature set, I looped through JSON features and used arcpy.JSONToFeatures_conversion and appended them to a feature class. Everything went well. Thanks again for your prompt response.
Hi Abhi. That’s great news! I might look into JSONToFeatures_conversion. -mike
Dear Michael,
Thank you for sharing such a wonderful tool.
I’ve almost reached the end of the Internet spending countless hours trying to find a solution / understand how it would be possible to implement a script to get the much needed data and here it is.
As a remark (feedback) please kindly note that as in my case the no. of records was around 5.000, although I tried with maxrc = 1000/500/200 etc, it was only when I set maxrc = 1 (one by one) all records where transferred successfully.
In the rest of cases there was everytime a random record that was skipped (no errors).
I wish you all the best.
Hi Iulian. I’m glad you found a solution from this site! -mike
Dear Michael,
I tried running your tool on the follow
https://gis.ohiodnr.gov/arcgis_site2/rest/services/OIT_Services/odnr_landbase_v2/MapServer/4
and kepth getting the “KeyError: ‘objectIdFieldName'” as several have mentioned, I have tried solutions you provied and was not able to get it working, any ideas what I might be missing?
Hi Bee. Just going to the query page for the map service at https://gis.ohiodnr.gov/arcgis_site2/rest/services/OIT_Services/odnr_landbase_v2/MapServer/4/query to find out how many records (Where set to 1=1 , do not return geometry, return county only) you get about 6.2 million records! My guess because there are so many, the map service could not respond with all the unique record numbers, thus the script errors. After further testing, yes it had a problem and I get a code 500 error “error performing query operation”. You really want to grab all of them?
My goal is to grab all.
I am open to suggestions also.
Because of the large dataset, I would contact the GIS group at Ohio DNR and see if they would send you a geodatabase for you to use. See contact info at http://geospatial.ohiodnr.gov/contacts-about-us/contacts-and-staff . If you don’t want to go this route, then modify the script under the get object ids section and change the following lines:
# j = urllib2.urlopen(urlstring)
# js = json.load(j)
idfield = “OBJECTID”
idlist = range(1,6265911)
The # comments out the line so it will not execute. I figured out the highest record number (6265910) so add one more to get a range of numbers from 1 to 6265910, which would be your record numbers. Good luck! -mike
Hello Mike,
what will be the implication of changing returnGeometry=true to false, will it allow me to still load a json flat file and possibly load faster?
By the way the current suggestion is working, just wondering how to tweak and make faster.
If you change returnGeometry to false, you will not get any point coordinates that represent the boundaries of the parcel polygons and the script will fail when it tries to save the records because it expects features to save. You cannot make the script run faster because it is at the mercy of the map service speed of responding to your many requests. Since you are dealing with millions of records, it will take some time. -mike
Thanks Mike.
I am running on python 2.7 (ArcMap) but not working
It’s probably your map service you are trying to access, not ArcMap.
Hi Michael,
I am getting error like this:
Record extract limit: 1000
Runtime error
Traceback (most recent call last):
File “”, line 19, in
KeyError: ‘objectIdFieldName’.
how to resolve this type of error and my map service path is :-
https://livingatlas.esri.in/server/rest/services/LivingAtlas/IND_Education/MapServer
Hi Manish. I think your issue would be solved if you use layer 0 in your baseURL. Remember, map services have layers and you need to specify what layer number you want. Your map service only has one layer, which is layer 0. Try using https://livingatlas.esri.in/server/rest/services/LivingAtlas/IND_Education/MapServer/0 and see if the script works.
thank you Michael for the advice and i m also trying in ArcGis pro with this code but getting error. Please check the code and suggest me what to modify.
CODE:
import urllib.parse, urllib.request, os, arcpy
url = “https://livingatlas.esri.in/server/rest/services/LivingAtlas/IND_Education/MapServer/0 ”
params = {‘where’: ‘1=1’,
‘geometryType’: ‘esriGeometryEnvelope’,
‘spatialRel’: ‘esriSpatialRelIntersects’,
‘relationParam’: ”,
‘outFields’: ‘*’,
‘returnGeometry’: ‘true’,
‘geometryPrecision’:”,
‘outSR’: ”,
‘returnIdsOnly’: ‘false’,
‘returnCountOnly’: ‘false’,
‘orderByFields’: ”,
‘groupByFieldsForStatistics’: ”,
‘returnZ’: ‘false’,
‘returnM’: ‘false’,
‘returnDistinctValues’: ‘false’,
‘f’: ‘pjson’
}
encode_params = urllib.parse.urlencode(params).encode(“utf-8”)
response = urllib.request.urlopen(url, encode_params)
json = response.read()
with open(“mapservice.json”, “wb”) as ms_json:
ms_json.write(json)
ws = os.getcwd() + os.sep
arcpy.JSONToFeatures_conversion(“mapservice.json”, ws + “mapservice.shp”)
ERROR:
Traceback (most recent call last):
File “”, line 32, in
File “c:\users\posterscope\appdata\local\programs\arcgis\pro\Resources\arcpy\arcpy\conversion.py”, line 472, in JSONToFeatures
raise e
File “c:\users\posterscope\appdata\local\programs\arcgis\pro\Resources\arcpy\arcpy\conversion.py”, line 469, in JSONToFeatures
retval = convertArcObjectToPythonObject(gp.JSONToFeatures_conversion(*gp_fixargs((in_json_file, out_features, geometry_type), True)))
File “c:\users\posterscope\appdata\local\programs\arcgis\pro\Resources\arcpy\arcpy\geoprocessing\_base.py”, line 506, in
return lambda *args: val(*gp_fixargs(args, True))
arcgisscripting.ExecuteError: ERROR 001558: Error parsing json file ‘mapservice.json’.
Failed to execute (JSONToFeatures).
The code is only for arcpy that comes with ArcGIS Desktop (ArcMap). It was not designed to run with the version that comes with ArcGIS Pro. I did notice that the map service is a little slow. When I changed the maxrc variable to 100, it worked just fine:
#maxrc = int(js[“maxRecordCount”])
maxrc = 100
hello Michael, i am running this code on ArcGis Pro (PYTHON 3.8) but getting error.
CODE:
import arcpy
import urllib.parse
import urllib.request
import json
from urllib.parse import urlencode
from urllib.request import urlopen
# Setup
arcpy.env.overwriteOutput = True
baseURL = “https://livingatlas.esri.in/server/rest/services/LivingAtlas/IND_Education/MapServer/0”
fields = “*”
outdata = “C:/Users/PosterScope/Documents/ArcGIS/Projects/MyProject/MyProject.gdb”
# Get record extract limit
urlstring = baseURL + “?f=json”
j = urllib.request.urlopen(urlstring)
js = json.load(j)
maxrc = 100
print (“Record extract limit: %s” % maxrc)
# Get object ids of features
urlstring = {‘idlist’:’1=1′,’returnIdsOnly’:’true’,’f’: ‘pjson’}
encode_params = urllib.parse.urlencode(urlstring).encode(“utf-8”)
j = urllib.request.urlopen(urlstring)
js = json.load(j)
idfield = js[“objectIdFieldName”]
idlist = range(1, 693 + 1)
idlist.sort()
numrec = len(idlist)
print (“Number of target records: %s” % numrec)
# Gather features
print (“Gathering records…”)
#fs = dict()
merge_list = []
for i in range(0, numrec, maxrc):
torec = i + (maxrc – 1)
if torec > numrec:
torec = numrec – 1
fromid = idlist[i]
toid = idlist[torec]
where = “{} >= {} and {} <= {}".urllib.parse.urlencode(idfield, fromid, idfield, toid).encode("utf-8")
print (" {}").urllib.parse.urlencode(where).encode("utf-8")
urlstring = {'returnGeometry':'true','outFields':'{}','f':'pjson'}
urllib.parse.urlencode(urlstring).encode("utf-8")
#fs[i] = arcpy.FeatureSet()
#fs[i].load(urlstring)
fs = arcpy.FeatureSet()
fs.load(urlstring)
tempdata = outdata + str(i)
print (" Copying features…")
arcpy.CopyFeatures_management(fs, tempdata)
merge_list.append(tempdata)
# Save features
print ("Saving features…")
#fslist = []
#for key,value in fs.items():
#fslist.append(value)
arcpy.Merge_management(fslist, outdata)
print ("Done!")
ERROR:
Record extract limit: 100
Traceback (most recent call last):
File "”, line 28, in
File “C:\Users\PosterScope\AppData\Local\Programs\ArcGIS\Pro\bin\Python\envs\arcgispro-py3\lib\urllib\request.py”, line 223, in urlopen
return opener.open(url, data, timeout)
File “C:\Users\PosterScope\AppData\Local\Programs\ArcGIS\Pro\bin\Python\envs\arcgispro-py3\lib\urllib\request.py”, line 517, in open
req.timeout = timeout
AttributeError: ‘dict’ object has no attribute ‘timeout’
As I said before, the script I wrote in this article was for the Python version that comes with ArcGIS Desktop (ArcMap).
when I am running this code in ArcMap10.7 (desktop) I m getting error. Please check and give me a suggestion were to rectify my errors.
CODE:
import arcpy
… import urllib2
… import json
…
… # Setup
… arcpy.env.overwriteOutput = True
… baseURL = “https://livingatlas.esri.in/server/rest/services/LivingAtlas/IND_Education/MapServer/0”
… fields = “*”
… outdata = “C:/Users/Admin/Documents/ArcGIS/Default.gdb”
…
… # Get record extract limit
… urlstring = baseURL + “?f=json”
… j = urllib2.urlopen(urlstring)
… js = json.load(j)
… maxrc = 100#int(js[“maxRecordCount”])
… print “Record extract limit: %s” % maxrc
…
… # Get object ids of features
… where = “1=1”
… urlstring = baseURL + “/query?where={}&returnIdsOnly=true&f=json”.format(where)
… j = urllib2.urlopen(urlstring)
… js = json.load(j)
… idfield = js[“objectIdFieldName”]
… idlist = js[“objectIds”]
… idlist.sort()
… numrec = len(idlist)
… print “Number of target records: %s” % numrec
…
… # Gather features
… print “Gathering records…”
… fs = dict()
… for i in range(0, numrec, maxrc):
… torec = i + (maxrc – 1)
… if torec > numrec:
… torec = numrec – 1
… fromid = idlist[i]
… toid = idlist[torec]
… where = “{} >= {} and {} = 1 and objectid = 101 and objectid = 201 and objectid = 301 and objectid = 401 and objectid = 501 and objectid = 601 and objectid <= 693
Saving features…
Runtime error Traceback (most recent call last): File "”, line 49, in File “c:\program files (x86)\arcgis\desktop10.7\arcpy\arcpy\management.py”, line 4496, in Merge raise e ExecuteError: ERROR 999998: Unexpected Error.
Your outdata variable needs a feature class name to store in your gdb, something like outdata = “C:/Users/Admin/Documents/ArcGIS/Default.gdb/education”. You changed the where variable in the “Gather features” section of the code. Put it back to the original setting as outlined in the original code in this article.
Thank you Michael, the code work perfectly on ArcMap.The changes you mentioned above really work for me.Thank you so much for helping Michael and the code executed perfectly. But when I am opening the attribute table after extracting features, 1 column is missing (last column: SHAPE). Can you please help me with that how to solve it?
Hi Manish. I’m glad it worked out. The Shape field should be there. I can see it in ArcCatalog in my data.
Hi Michael, yes the shape field is showing in ArcCatalog (attribute table) but when I am exporting to excel or in JSON format, the shape field is not showing. All fields appeared in the excel spreadsheet but the only column shape field not showing. same case when I am converting it into JSON. please suggest a solution on how to resolve it? so that all the fields should appear in my excel spreadsheet.
Mike,
I am getting the following two errors depending on the service I use:
Traceback (most recent call last):
File “G:\DATA\RIVERSIDE_COUNTY\Backend_Automation\Test\Scipts\Download_Data_Test_v6.py”, line 56, in
fs[i].load(urlstring)
File “d:\program files (x86)\arcgis\desktop10.3\ArcPy\arcpy\arcobjects\arcobjects.py”, line 175, in load
return convertArcObjectToPythonObject(self._arc_object.Load(*gp_fixargs(args)))
RuntimeError: RecordSetObject: Cannot open table for Load
OR….
Traceback (most recent call last):
File “G:\DATA\RIVERSIDE_COUNTY\Backend_Automation\Test\Scipts\Download_Data_Test_v6.py”, line 26, in
j = urllib2.urlopen(urlstring)
File “C:\Python27\ArcGIS10.3\lib\urllib2.py”, line 127, in urlopen
return _opener.open(url, data, timeout)
File “C:\Python27\ArcGIS10.3\lib\urllib2.py”, line 404, in open
response = self._open(req, data)
File “C:\Python27\ArcGIS10.3\lib\urllib2.py”, line 422, in _open
‘_open’, req)
File “C:\Python27\ArcGIS10.3\lib\urllib2.py”, line 382, in _call_chain
result = func(*args)
File “C:\Python27\ArcGIS10.3\lib\urllib2.py”, line 1222, in https_open
return self.do_open(httplib.HTTPSConnection, req)
File “C:\Python27\ArcGIS10.3\lib\urllib2.py”, line 1184, in do_open
raise URLError(err)
URLError:
The first error is from some test public data that has approx. 3k features, service url:
https://sampleserver6.arcgisonline.com/arcgis/rest/services/Census/MapServer/2
The second error is from the data I plan to extract with approx. 58k features, service url:
https://gis.countyofriverside.us/arcgis_public/rest/services/OpenData/ParcelBasic/MapServer/6
In both cases I tried adjusting the max record count down, however that did not clear out the issue. Any assistance would be greatly appreciated.
Thanks,
Jared
Hi Jared. I found the first URL very sensitive to both the max records and how the where clause was formatted. I had to make 3 changes to the script. First I added the line “import urllib” at the beginning of the script. You will use this library to format the where clause to a “safe” format. Next change your maxrc variable to 150. I found grabbing 150 record chuncks worked for me. Lastly, you need to change the urlstring variable in the Get Features section of the code, specifically it should look like this:
urlstring = baseURL + “/query?where={}&returnGeometry=true&outFields={}&f=json”.format(urllib.quote_plus(where),fields)
Note the change is the where variable in .format(), from “where” to “urllib.quote_plus(where)”. That will take the value of the where variable and format it to be “safe”, so something like this:
OBJECTID >= 1 and OBJECTID <= 150
looks like this:
OBJECTID+%3E%3D+1+and+OBJECTID+%3C%3D+150
It is strange why some map services will work just fine without it, but others need safe characters. Go figure.
As for your other URL, that worked just fine for me without any modifications to the script. I was able to grab all the features. Maybe their map service was very slow at the time? Note sure. -mike
Mike, you’re an Angel of Mercy! THANK you!
Hi Lisa. I’m glad it helped you out! -mike
Good morning Mike:
I have used a number of different ways to try and pull data off an EPA map service over the past few days. I also am running into the dreaded “RuntimeError: RecordSetObject: Cannot open table for Load” error, but none of the suggestions I read about above have worked.
I am running ArcPro, and have modified the script to run in Python 3 (I think). I made the OIDS and OIDLIST mods (line 42 and 44), as well as changing the URL string in line 49 (urllib.quote_plus doesn’t work in Py3, it must be urllib.parse.quote_plus). NOTE its tough to line code up in this text box, sure you can see that. 😉
If I need to backpedal to Python 2, I;ll do that, but I;d prefer to avoid the headache. Iam working on a Windows 10 machine inside Spyder 4, using a MiniConda environment that is ArcPy aware.
Based on all the reading from above, I know I have to be VERY close to making this work, but I am not a web dev or coder by trade; I could use a shove in the right direction. I really think this has to do with how many records I am asking for at once, and how I am formatting the URL string. But I;m just not quite getting it.
The service in question is at:
https://gispub.epa.gov/arcgis/rest/services/OW/ATTAINS_Assessment/MapServer
The desired layers are Lines (1) and Areas (2). The Lines layer has about 600K features, but other method I have pulled almost the entire layer before erroring out. Areas is about 70k features.
If there answer is above and I missed it, I apologize. I’m a little bleary-eyed from trying to code this correctly. 😉 Any assistance would be very helpful. Thanks.
1 import arcpy
2 import urllib
3 import json
4
5 # Clear Screen
6 print(“\033[H\033[J”)
7
8 # Setup
9 arcpy.env.overwriteOutput = True
10 baseURL = “https://gispub.epa.gov/arcgis/rest/services/OW/ATTAINS_Assessment/MapServer/2”
11 fields = “*”
12 outdata = “C:/Users/Nathan.Murry/NOAA/GIS/ArcPro_Sandbox/ArcPro_Sandbox.gdb/testbath”
13
14 # Get record extract limit
15 urlstring = baseURL + “?f=json”
16 j = urllib.request.urlopen(urlstring)
17 js = json.load(j)
18 maxrc = 50 #int(js[“maxRecordCount”])
19 print(“Record extract limit: %s” % maxrc)
20
21 # Get object ids of features
22 where = “1=1”
23 urlstring = baseURL + “/query?where={}&returnIdsOnly=true&f=json”.format(where)
24 j = urllib.request.urlopen(urlstring)
25 js = json.load(j)
26 idfield = js[“objectIdFieldName”]
27 idlist = js[“objectIds”]
28 idlist.sort()
29 numrec = len(idlist)
30 print(“Number of target records: %s” % numrec)
31
32 # Gather features
33 print(“Gathering records…”)
34 fs = dict()
35 for i in range(0, numrec, maxrc):
36 torec = i + (maxrc – 1)
37 if torec > numrec:
38 torec = numrec – 1
39 fromid = idlist[i]
40 toid = idlist[torec]
41 where = “{} >= {} and {} <= {}".format(idfield, fromid, idfield, toid)
42 oidlist = idlist[i:torec + 1]
43 print(" {}".format(where))
44 oids = ','.join(str(e) for e in oidlist)
45 print(oids)
46
47 #urlstring = baseURL + "/query?objectIds={}&returnGeometry=true&outFields={}&
f=json".format(oids,fields)
48 #urlstring = baseURL + "/query?where={}&returnGeometry=true&outFields={}&
f=json".format(where,fields)
49 urlstring = baseURL + "/query?where={}&returnGeometry=true&outFields={}&
f=json".format(urllib.parse.quote_plus(where),fields)
50
51 fs[i] = arcpy.FeatureSet()
52 fs[i].load(urlstring)
53
54 # Save features
55 print("Saving features…")
56 fslist = []
57 for key,value in list(fs.items()):
58 fslist.append(value)
59 arcpy.Merge_management(fslist, outdata)
60 1print("Done!")
Hi Nate. I took a look at your script and the map services. Those EPA map services are sometimes slow and will cause problems, so changing the maxrc variable to something small was a good idea, but will take some time to get all the features. I was able to get all the features for layer 2 (Areas) using a maxrc of 100. It took about 45 minutes to get all 67,568 records. I would guess a maxrc of 100 would also need to be used for layer 1 (Lines).
I ran your script using Python 3 that is installed with ArcGIS Pro. I did have to change one thing, I changed “import urllib” to “import urllib.request” to get your script to work for me. I’m using ArcGIS Pro 2.6.2 which has Python 3.6.10. This is what I did at the Windows command prompt to run your script using ArcGIS Pro:
C:\your_arcgispro_install_location\bin\Python\Scripts\propy.bat your_script.py
I hope this works for you. Good luck. -mike
Hi Mike:
Thank you so much for getting back to me. You have given me hope that this can work. Unfortunately, I am not quite able to get this going. First, a few more details. I am running ArcPro 2.6.0 and Python 3.6.12. I do not have rights over my machine, but I do have access to a machine that I do have rights over, and I might try that out as well.
I made ONLY the changes you explicitly suggested (“import urllib” to “import urllib.request”). I then rnn the script from inside Spyder (linked to the ArcPro Python environment) and I also ran it on the command line as you suggested. Both times returned the following:
Record extract limit: 100
Number of target records: 67568
Gathering records…
OBJECTID >= 67501 and OBJECTID <= 67568
67501,67502,67503,67504,67505,67506,67507,67508,67509,67510,67511,67512,67513,67514,67515,67516,67517,67518,67519,67520,67521,67522,67523,67524,67525,67526,67527,67528,67529,67530,67531,67532,67533,67534,67535,67536,67537,67538,67539,67540,67541,67542,67543,67544,67545,67546,67547,67548,67549,67550,67551,67552,67553,67554,67555,67556,67557,67558,67559,67560,67561,67562,67563,67564,67565,67566,67567,67568
Traceback (most recent call last):
File "C:/scrapejson.py", line 56, in
fs[i].load(urlstring)
File “C:\Program Files\ArcGIS\Pro\Resources\ArcPy\arcpy\arcobjects\arcobjects.py”, line 422, in load
return convertArcObjectToPythonObject(self._arc_object.Load(*gp_fixargs(args)))
RuntimeError: RecordSetObject: Cannot open table for Load
Both runs tripped over the same line, which would be 52 above:
fs[i].load(urlstring)
You said this works for you, and we have a very similar environment. Like you, I will not concede victory to w ‘wretched computer’ when I know someone made it work. I will try this on my other workstation (that I have rights over) but I am curious if you have any other ideas or tricks. Than you again!
–Nate
Hi Mike:
OK, update: I ran the script on my other workstation that I have rights on (ArcPro 2.6.2, Python 3.6.12), and it worked! However, it only grabbed the number records I asked for (100) and then stopped. Please forgive my ignorance, but how do I configure the script to keep running until it gets all the records, as you did?
In passing, its wonderful to know my configured work machine impedes my actual work. Thanks again for your help.
–Nate
Mike:
NEVERMIND on everything. Indenting bit me in the tail. Now I am running and we’ll see if it works through all the records. It’s been a long week of coding. How on earth could I forget indenting. Anyway, thanks again; you and this script have been extremely helpful.
–Nate
Hi Nate. I’m glad you figured it out! I decided to try the script to grab layer 1 (Lines) with a maxrc set to 100. It got all the way to records 242701 to 242800 and failed. I guess their map server started slowing down and could not respond with the records. Things can get dicey when you are dealing with thousands of records and a slow map server. There is always another option … call them and see if they can give you the data! All the best. -mike
I was thinking, in your Spyder environment maybe doing the following would work (I have not tested it):
Add “import requests” at the top of your script, then change the line “fs[i].load(urlstring)” to this:
r = requests.get(urlstring)
fs[i].load(r.json())
Maybe that would work for you. -mike
Hi Mike:
I will give that a shot and report back. I would indeed prefer to work in my Spyder environment if possible, and was a bit perplexed why it was failing. However, the fact remains that I have a serviceable solution, which really made my week.
–Nate
Hi Mike:
I also ran into the same issue with the Lines layer. That layer has vexed me to the end, but it has now been conquered as well.
The key with this entire service is to good copy of everything. Updates would happen once a month or so, so its not a big deal to have a perfectly automatic (or elegant) updating system; I just need a good base layer.
With that in mind, I got around the issue my modifying ‘numrec’ (line 29) to a hard-coded maximum record number, and then modifying ‘i’ (line 35 for/loop) to where I start pulling records. That way, I decide where to start and end a record pull, which allows me to pull the entire service in (for example) 75,000 record chunks and them stitch them together in ArcPro. I can do most all of the ‘chunking’ and stitching programmatically as well. Mission accomplished.
Thank you so much for your helpful tips. Have a great weekend.
–Nate
Pingback: Easy Way to Bypass REST API Query Limits | by Ablajan Sulaiman | Feb, 2021 - YTC
Hi Mike,
I ran the initial code of extracting features where only 2000 records were getting exported. Now when I am trying to run it to get all the records, it is giving the
“CertificateError: hostname ‘weba.co.clayton.ga.us’ doesn’t match either of ‘*.claytoncountyga.gov’, ‘claytoncountyga.gov'” error.
It did for the shorter version too, but somehow I was able to get rid of it. Not so successful on the longer one. Help!
I don’t think you can do much because it is a website certificate issue on their server.
Thank you for your quick response Mike! How come it doesnt have issues while running the shorter version vs this longer version issue?
I’m not sure. Try limiting the number of features you bring over and see if that helps.
Hello, thank you for providing this, it has helped a lot in the past. I am currently trying to use this to extract certain layers in a feature service (found here: https://cteco.uconn.edu/ctmaps/rest/services/Parcels/Parcels/FeatureServer). Is there a way to iterate over a feature service for the number of layers?
Thank you,
Adam
Wow, 177 layers! Kind of goes against ESRI’s best practices for efficient map services. Yes, you can modify the code to read in the layer names and numbers, then iterate extracting features from each layer and saving. Looks like these are all parcels, so you could save them all into one feature class. I don’t have time to write the code to do it, but if you have a smart python person, they could do it for you. The urlstring variable used in the get record extract limit section would be the same, but you would need to get at the layer data, specifically the JSON data returned by https://cteco.uconn.edu/ctmaps/rest/services/Parcels/Parcels/FeatureServer/?f=json . Once collected, you would iterate through the different layers by ID number and extract the data. -mike
Hello Mike,
Thank you for the quick reply. I know the number if layers is not ideal, when it comes to parcels in Connecticut the data standards are not well represented so each town has a slightly different way they represent the parcel data. I was able to get the code to work and iterate over each layer in the feature service, however after awhile I receive a KeyError: ‘maxRecordCount’ message. I have copied my code below, I am not sure why after x iterations do I receive this error.
Thank you,
Adam
——————————————————————————————————————————————————————–
import arcpy
import urllib2
import json
from arcpy import env
env.workspace = “C:\Dissertation\Chapter_1_SolarSiting\Data\CT_Data”
inFeature = “Solar_Towns_CT.shp”
field = “TOWN_NO”
town = “TOWN”
# Use SearchCursor with list comprehension to return a
# unique set of values in the specified field
values = [row[0] for row in arcpy.da.SearchCursor(inFeature, field)]
uniqueValues = set(values)
print(uniqueValues)
town_name = [row[0] for row in arcpy.da.SearchCursor(inFeature, town)]
uniqueTowns = set(town_name)
converter = lambda x: x.replace(‘ ‘, ‘_’)
uniqueTowns = list(map(converter, uniqueTowns))
print(uniqueTowns)
Town_dictionary = dict(zip(uniqueValues, uniqueTowns))
print(Town_dictionary)
for townNumber, townName in Town_dictionary.items():
# Setup
arcpy.env.overwriteOutput = True
baseURL = “https://cteco.uconn.edu/ctmaps/rest/services/Parcels/Parcels/FeatureServer/%s” % (townNumber)
fields = “*”
outdata = “C:/Dissertation/Chapter_1_SolarSiting/Data/CT_Data/CT_Parcels/Parcels.gdb/%s” % (townName)
print “Now working on %s” % (townName)
# Get record extract limit
urlstring = baseURL + “?f=json”
j = urllib2.urlopen(urlstring)
js = json.load(j)
maxrc = int(js[“maxRecordCount”])
print “Record extract limit: %s” % maxrc
# Get object ids of features
where = “1=1”
urlstring = baseURL + “/query?where={}&returnIdsOnly=true&f=json”.format(where)
j = urllib2.urlopen(urlstring)
js = json.load(j)
idfield = js[“objectIdFieldName”]
idlist = js[“objectIds”]
idlist.sort()
numrec = len(idlist)
print “Number of target records: %s” % numrec
# Gather features
print “Gathering records…”
fs = dict()
for i in range(0, numrec, maxrc):
torec = i + (maxrc – 1)
if torec > numrec:
torec = numrec – 1
fromid = idlist[i]
toid = idlist[torec]
where = “{} >= {} and {} <= {}".format(idfield, fromid, idfield, toid)
print " {}".format(where)
urlstring = baseURL + "/query?where={}&returnGeometry=true&outFields={}&f=json".format(where,fields)
fs[i] = arcpy.FeatureSet()
fs[i].load(urlstring)
# Save features
print "Saving features…"
fslist = []
for key, value in fs.items():
fslist.append(value)
arcpy.Merge_management(fslist, outdata)
print "Done!"
I find their server to be slow to respond. Perhaps when that happens, sometimes you will get a blank page or error from the URL for the record limit query, so there will not be a maxRecordCount key in the returned JSON. You can always verify by printing the js variable to see if that is true. Since you already know the max record count is 1000, you can always hard code the maxrc variable to 1000 and comment out the code before it. -mike
Hello Mike,
This helped and I greatly appricate it. A new issue I am running up against is trying to index specific layers in this feature service based on a list of town numbers. Each town in Connecticut has an associated number, I assumed they would match with the number in the layer list of the feature service, they do not. Do you know of a way to resolve this issue? Can I query based on the name of the layer in the feature service and not the layer or ID number?
Thank you for all your help so far.
Adam
To extract data, you have to use the layer number (ID). However, when you save the data on your end, you can name it whatever you want, like the layer name which I assume is the town. What’s interesting is you can look at each layer in the ArcGIS Online map viewer. If you turn on the attribute table, you will see the attributes for the parcels. What’s funny is that there is no standardization, each layer has their own set of attributes. I do see town numbers, but some use the attribute Town, others use MUNICIPALI, and others use Municipality. I guess after you download each layer, you would need to standardize the attributes on your end to “fix” it. -mike
Hello Mike,
I hope all is well. I am back at the parcel download for Connecticut after revising our initial search criteria for our project. However, I am running into a new issue. After some time, almost at random it seems, my code throws an error “Error 000210 cannot create output”. The strange part is that path is the same for each iteration only the name of the feature class changes, the scheme is %s_proj % (townname). Would you happen to know what might be causing this issue? Thank you.
Hi Adam. Off the top of my head maybe something is locking your data, like another program trying to access your data while your script is running? Doing a Google search for “arcgis Error 000210 cannot create output” might give a clue in your situation. -mike
Hello Mike,
Looking into it now, I checked paths and made some adjustments. All programs are closed but that is not to say something is running in the background that I am unaware of. Thank you for the suggestions.
The only other thing I can think of is that you have anti-virus software running and checking your reads and writes. Another option is to slow down your python script using time.sleep() for a second or two before a read or write. -mike
Hello Mike,
Slowing down the python script is an interesting idea I did not know that was a possibility. I was however able to get it to work. I believe there were some small python syntactical errors (paths with / and not \) and placing the r before a path name. I have a few more runs before I can call it totally good. But for now those two things seemed to help.
A bit late to this party but this code was exactly what I needed! Thank you for sharing. It was pretty much a simple copy and paste & run for me.
Great to hear it still works! -mike
Hi from a Colorado local gov member 🙂
Your script was exactly what I’m looking for.
I did make a couple of adjustments since I’m using Python 3.
In 3, urllib2.urlopen(urlstring) is now –> urllib.request.urlopen(urlstring).
Thanks for sharing!
Hi. I am glad it helped you out! -mike
I found a few comments mentioning issues with ArcGIS Pro’s version of python. Working with a new computer, which only has Pro installed, I decided to try and convert the code to work with Python 3. Below is the provided example with the necessary changes to work with ArcGIS Pro. I hope this helps.
import arcpy
import urllib.request, urllib.error, urllib.parse
import json
# Setup
arcpy.env.overwriteOutput = True
baseURL = “http://services.gis.ca.gov/arcgis/rest/services/Environment/Wildfires/MapServer/0”
fields = “*”
outdata = “H:/cal_data/data.gdb/testdata”
urlstring = baseURL + “?f=json”
j = urllib.request.urlopen(urlstring)
js = json.load(j)
maxrc = int(js[“maxRecordCount”])
print(“Record extract limit: {}”.format(maxrc))
# Get object ids of features
where = “1=1”
urlstring = baseURL + “/query?where={}&returnIdsOnly=true&f=json”.format(where)
j = urllib.request.urlopen(urlstring)
js = json.load(j)
idfield = js[“objectIdFieldName”]
idlist = js[“objectIds”]
idlist.sort()
numrec = len(idlist)
print(“Number of target records: {}”.format(numrec))
# Gather features
print (“Gathering records…”)
fs = dict()
for i in range(0, numrec, maxrc):
torec = i + (maxrc – 1)
if torec > numrec:
torec = numrec – 1
fromid = idlist[i]
toid = idlist[torec]
where = “{} >= {} and {} <= {}".format(idfield, fromid, idfield, toid)
print(" {}".format(where))
urlstring = baseURL + "/query?where={}&returnGeometry=true&outFields={}&f=json".format(where,fields)
fs[i] = arcpy.FeatureSet()
fs[i].load(urlstring)
# Save features
print ("Saving features…")
fslist = []
for key,value in list(fs.items()):
fslist.append(value)
arcpy.Merge_management(fslist, outdata)
print ("Done!")
Thanks Adam! You can use the Analyze Tools for Pro to check Python 2 code that was used in ArcGIS Desktop 10.x. See https://pro.arcgis.com/en/pro-app/latest/tool-reference/data-management/analyzetoolsforpro.htm . It uses the Python 2to3 utility to review Python code. See https://docs.python.org/3/library/2to3.html . -mike
Hi, Mike.
Could you help me to solve my problem encountered an error while I’m running in this part : “fs[i].load(urlstring)” it turns me an error : “RuntimeError: RecordSetObject: Cannot open table for Load”
I use Pyhton 3
And i’ve set up similir with your code, but I make a modification because using urllib, not urllib2.
Hi Thomas. What is the URL for the map service you are trying to access? Just by looking at the error, it seems it cannot get a reply from the service so there is nothing to load.
Hola, como estás?
Muchas gracias por compartir tu script.
Al final del procedimiento me sale este error:
TypeError: is not JSON serializable
¿Qué puedo hacer en este caso?
Not sure. However, take a look at this: https://pynative.com/make-python-class-json-serializable/